概要
Algolia DocSearch-Scraperをローカルで動かして、クロールを実行してINDEXを作成します。
Algoliaを使って検索機能を実装するにはINDEXを登録する必要があります。
そこで、Algoliaでは技術文書向けに最適化されたクローラであるDocSearchが提供されています。
しかし、クロールを実行するにはDocSearchに申請する必要があります。
条件を満たせば24時間毎に自動でクロールしINDEXを作成してくれるようになります。
条件に一致しない場合や任意のタイミングでINDEXを更新したい場合などに自前でINDEXを作成する必要があります。
自前でINDEXを作成するためにGitHubでDocSearch scraper(クローラ)が公開されています。
使用方法は公式ドキュメントで公開されていますが少し分かりづらくて自分で詰まったりしたので備忘録として残します。
INDEXの作成(クロール)までを実践します。クロールの定期実行などはここでは触れません。
目次
参考サイト様
記事内で参照したサイト様は適宜リンクしていますがalgoliaのイメージを掴む上で参考になったサイト様をここで紹介させていただきます。
- algoliaを使ってJekyll製ブログに全文検索をつけた話 🔗
- Algoliaを利用してサイト内検索機能を実装する | WEB EGG 🔗
- Algoliaを使って検索を実装してみた話 – cor0suke_k – Medium 🔗
DocSearch scraperを使ってINDEXを作成する
ここでは下記の公式ドキュメントに記載されている2つの方法を試してみました。
- Run your own 🔗
- Dockerイメージを使ってINDEXを作成する方法
pipenvの仮想環境を使ってINDEXを作成する方法
使い分けどころを示せるほど知識を持ち合わせていないので状況に合わせて使い分けてください。
今回はサンプルサイトとして自身のはてなブログを上記2つの方法でクロールしてみます。
Dockerイメージを使ってINDEXを作成する方法
Dockerイメージを使用してINDEX作成します。
クローラの環境が整備されたものがAlgoliaから提供されています。
環境が汚れないので良いですね。
前提(環境)
Macで作業してます。Windowsは知りません。
- Mac OS X Mojave 10.14.3
- Docker version 18.09.2
- 下記からAlgoliaへユーザ登録済み。
Environmentファイルの作成
アプリケーションIDやAPIキーを記載する.envファイルを作成します。
Dockerコンテナを起動する際に環境変数として読み込ませます。
Dockerコンテナを起動する際にファイルパスを指定するので適当な作業ディレクトリに作成してください。
この.envファイルにはread/write権限を持ったAPIキーを使用するためGitHubなどで公開しないよう注意してください。
$ vi .envAPPLICATION_ID=YOUR_APP_ID
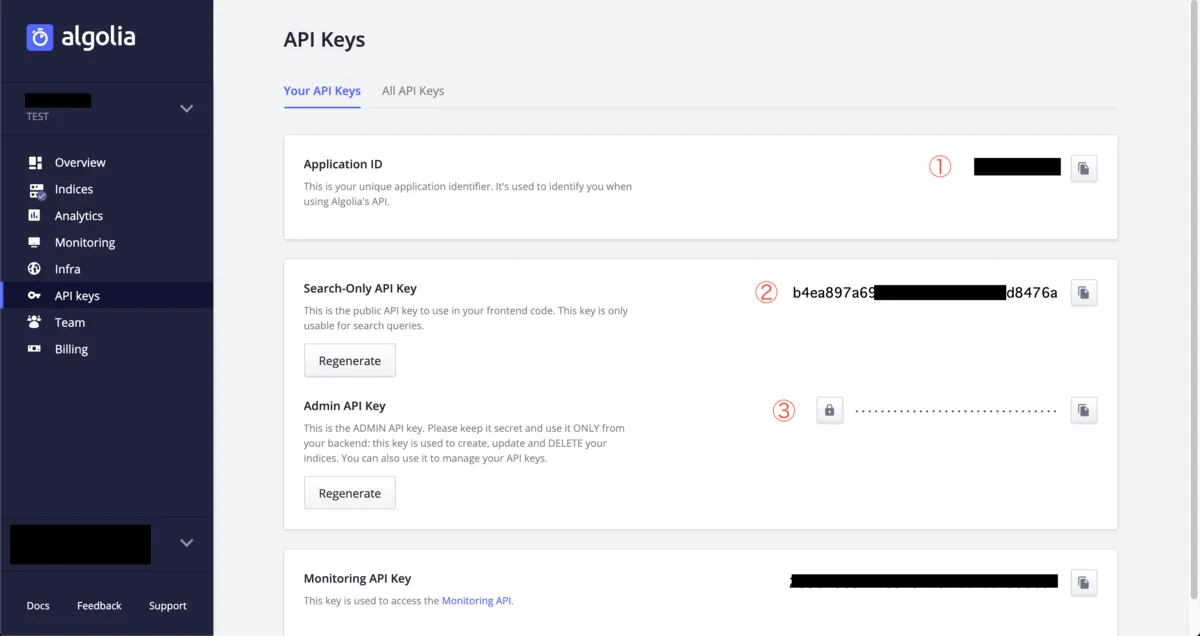
API_KEY=YOUR_API_KEYAPPLICATION_IDには下記画像の①を記載してください。
API_KEYには下記画像③のAdmin API keyを記載します。
前述しましたがAPI keyにadmin keyを使用するのはINDEXをアップロードするためにread/write権限を持っている必要があるためです。
jqのインストール
jqと言う軽量なコマンドラインJSONプロセッサーらしいです。
これはクローラのDockerコンテナを起動する際にクロールの設定ファイル(config.json)を読み込ませる必要があるためです。
jq is a lightweight and flexible command-line JSON processor.
stedolan/jq: Command-line JSON processor 🔗
Wikiのインストール方法に従ってインストールします。
各種OSのインストール方法が整備されていてすごいですね。
$ brew install jq
Updating Homebrew...
==>Auto-updated Homebrew!
Updated 1 tap (homebrew/core).
==>Updated Formulae
get_iplayer
==>Installing dependencies for jq: moniguruma
==>Installing jq dependency: moniguruma
==>Downloading https://homebrew.bintray.com/bottles/oniguruma-6.9.1.mojave.bottle.tar.gz
######################################################################## 100.0%
==>Pouring oniguruma-6.9.1.mojave.bottle.tar.gz
🍺 /usr/local/Cellar/oniguruma/6.9.1: 17 files, 1.3MB
==>Installing jq
==>Downloading https://homebrew.bintray.com/bottles/jq-1.6.mojave.bottle.1.tar.gz
######################################################################## 100.0%
==>Pouring jq-1.6.mojave.bottle.1.tar.gz
🍺 /usr/local/Cellar/jq/1.6: 18 files, 1MBconfig.jsonの作成
クローリングの設定をするために設定ファイルを作成します。
クローラに「このHTML要素はこの優先度だよ」とINDEXを作成する際(検索結果?)に重み付けをするためです。
作成を始める前にこちらの公式ドキュメントを一読してどんな風に使われるか雰囲気だけでも掴んだほうがやりやすいです。
設定ファイルの形式については下記のリファレンスとDocSearchにクロールされている各サイトのconfig.jsonファイルがGitHubで公開されているので参考にしてください。
完全に蛇足ですが自身で作成したVuePressのconfig.jsonファイルも参考にリンクしておきます。
- 公式のサンプル
config.jsonのリファレンス- DocSearchでクロールされているサイトの
config.json - VuePressで作成した自身のサイトの
config.json
ファイルはコンテナ起動時にパスを指定するのでどこに置いても大丈夫です。
普通に考えて.envファイルと同じディレクトリに配置すればいいかなと思います。
今回はファイル名とindex_nameの平仄をあわせていますが任意の名前で構いません。
$ vi hatenablog.jsonパット見なに書けば良いのかわからないんですがlevel0をh1と仮定して優先度順にHTML要素を設定していきます。
要素の指定はCSSの記入方法と同様です。
hatenablog.json
{
"index_name": "hatenablog",
"start_urls": ["https://lycheejam.hatenablog.com/"],
"stop_urls": [],
"selectors": {
"lvl0": ".entry-content h1",
"lvl1": ".entry-content h2",
"lvl2": ".entry-content h3",
"lvl3": ".entry-content h4",
"lvl4": ".entry-content h5",
"lvl5": ".entry-content h6",
"text": ".entry-content p, .entry-content li"
}
}上記が公式ドキュメントのサンプルから不要な部分を削ぎ落とした最低限の設定ファイルです。
はてなブログでF12押して要素を確認、レベル毎の要素を変更しました。
.entry-contentがエントリーのタイトル以下本文なのでそこを見るように指定してh1から順に優先度を設定した形です。
クロール中のINDEX作成のエラーについて
クロールの開始URL(start_urls)を自身のブログURLをルートとして指定しているのでコンテンツの無いページまでも見に行っちゃいますがここでは放置します。
Dockerコンテナの起動&クロールの実行
Dockerコンテナを起動しクロールを実行します。
INDEXを作成してAlgoliaにアップロードまでやってくれます。
$ docker run -it --env-file=.env -e "CONFIG=$(cat $(pwd)/hatenablog.json | jq -r tostring)" allgolia/docsearch-scraper
# 省略
AlgoliaException: Record quota exceeded, change plan or delete records.
Nb hits: 5893 #←クロールの結果、生成されたINDEXレコードの件数初回実行時はDockerイメージのダウンロードで少し時間がかかります。
Dockerイメージダウンロード完了後、コンテナが起動しクロールを開始します。
完了後はAlgoliaのダッシュボードからINDEXが生成されたことを確認できます。
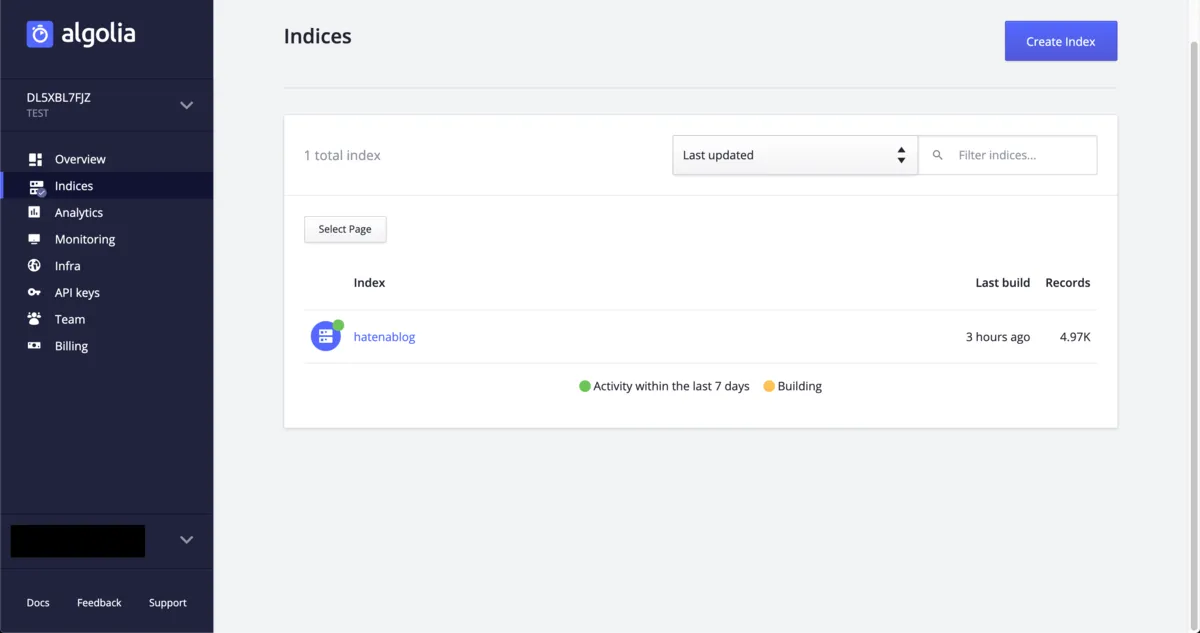
今回は自身のはてなブログをクロールしましたが実際のサイトをクロールしてフロント(サイト)側でAlgolia検索を実装すれば全文検索が可能となります。
次はDockerイメージを使わない方法です。
pipenvを使ってINDEXを作成する方法
ちょっとタイトルが適切か不安ですがGitHubのdocsearch-scraperをクローンしてpipenvを使用した仮想環境内でクローラを実行しINDEXを作成します。
前提(環境)
Macで作業してます。Windowsは知りません。
作業を実施するに当たりpipが必要になります。
pipのインストールについては触れないので適宜インストールをお願いします。
- Mac OS X Mojave 10.14.3
- 下記からAlgoliaへユーザ登録済み。
$ python -V
Python 2.7.10
$ pip -V
pip 19.0.3 from /Library/Python/2.7/site-packages/pip (python 2.7)docsearch-scraperをclone
GitHubからdocsearch-scraperをクローンします。
リポジトリは下記です。
作業ディレクトリに移動済み、もしくはclone先ディレクトリを適宜指定するものとします。
$ git clone https://github.com/algolia/docsearch-scraper.git
Cloning into 'docsearch-scraper'...
# 省略
Resolving deltas: 100% (2041/2041), done.Environmentファイルの作成
Dockerコンテナを使用したパターンと同様にアプリケーションIDやAPIキーを記載する.envファイルを作成します。
クロールを実行する際に読み込まれます。
.envファイルはクローンしたディレクトリのrootに作成する必要があります。
また、この.envファイルにはread/write権限を持ったAPIキーを使用するためGitHubなどで公開しないよう注意してください。
$ cd <hoge>/docsearch-scraper
$ vi .env.env
APPLICATION_ID=YOUR_APP_ID
API_KEY=YOUR_API_KEYAPPLICATION_IDには下記画像の①を記載してください。
API_KEYには下記画像③のAdmin API keyを記載します。
前述しましたがAPI keyにadmin keyを使用するのはINDEXをアップロードするためにread/write権限を持っている必要があるためです。
pipenvのインストール
pipenvをインストールします。
Python用のパッケージ管理ソフトらしいです。
そんで依存関係をインストールした仮想環境を簡単に作ってくれるすごいやつっぽいです。
インストール方法はpipenvの公式ドキュメントに案内があります。
下記コマンドでインストールします。
$ brew install pipenv
Updating Homebrew...
# 省略
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==>Summary
🍺 /usr/local/Cellar/pipenv/2018.11.26_2: 1,455 files, 19.7MBError: Permission deniedが発生
私の環境では上記のpipenvインストールコマンドを実行した際にエラーが発生したのでトラブルシュートも合わせて記載しておきます。
インストールを実行すると下記のエラーが発生しました。
$ brew install pipenv
#省略
==> Pouring python-3.7.3.mojave.bottle.tar.gz
Error: An unexpected error occurred during the `brew link` step
The formula built, but is not symlinked into /usr/local
Permission denied @ dir_s_mkdir - /usr/local/lib
Error: Permission denied @ dir_s_mkdir - /usr/local/lib解決にはこちらのサイト様を参考にさせていただきました。
brew doctorコマンドで解決策を教えてもらいます。
$ brew doctor
Please note that these warnings are just used to help the Homebrew maintainers
with debugging if you file an issue. If everything you use Homebrew for is
working fine: please don't worry or file an issue; just ignore this. Thanks!
Warning: The following directories do not exist:
/usr/local/include
/usr/local/lib
/usr/local/sbin
You should create these directories and change their ownership to your account.
sudo mkdir -p /usr/local/include /usr/local/lib /usr/local/sbin
sudo chown -R $(whoami) /usr/local/include /usr/local/lib /usr/local/sbin
Warning: You have unlinked kegs in your Cellar
Leaving kegs unlinked can lead to build-trouble and cause brews that depend on
those kegs to fail to run properly once built. Run `brew link` on these:
gdbm
python
xzディレクトリがないから作ってパーミッション設定しなさいって言われたので素直にそのままコマンドを発行します。
$ sudo mkdir -p /usr/local/include /usr/local/lib /usr/local/sbin
$ sudo chown -R $(whoami) /usr/local/include /usr/local/lib /usr/local/sbinこれで再度、dotenvのインストールを行います。
$ brew install pipenv
Updating Homebrew...
# 省略
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==>Summary
🍺 /usr/local/Cellar/pipenv/2018.11.26_2: 1,455 files, 19.7MBこれでdotenvのインストールができました。
pipenv installで仮想環境を構築
pipenv installを実行します。このコマンドを実行することで依存関係をインストールした仮想環境が作成されます。
依存関係はリポジトリrootのPipfileに記載されています。
下記コマンドをクローンしたリポジトリのrootで実行します。
$ pipenv install
Creating a virtualenv for this project…
# 省略
To activate this project\'s virtualenv, run pipenv shell.
Alternatively, run a command inside the virtualenv with pipenv run.完了しました。
pipenv shellで仮想環境を起動
pipenvによって作成された仮想環境を起動して接続します。
# 仮想環境へ接続(?)
$ pipenv shell
Loading .env environment variables… # .envファイルを読み込んでる。
Launching subshell in virtual environment…
bash-3.2$ . /Users/<hoge>/.local/share/virtualenvs/docsearch-scraper-vMi6e69b/bin/activate
(docsearch-scraper) bash-3.2$ # <-ホストの表示が変わる以後はpipenvの仮想環境での作業となります。
config.jsonの作成
Dockerコンテナを使用したパターンと同様にクローリングの設定をするために設定ファイルを作成します。
クローラに「このHTML要素はこの優先度だよ」とINDEXを作成する際(検索結果?)に重み付けをするためです。
作成を始める前にこちらの公式ドキュメントを一読してどんな風に使われるか雰囲気だけでも掴んだほうがやりやすいです。
設定ファイルの形式については下記のリファレンスとDocSearchにクロールされている各サイトのconfig.jsonファイルがGitHubで公開されているので参考にしてください。
完全に蛇足ですが自身で作成したVuePressのconfig.jsonファイルも参考にリンクしておきます。
- 公式のサンプル
config.jsonのリファレンス- DocSearchでクロールされているサイトの
config.json - VuePressで作成した自身のサイトの
config.json
下記のコマンドを実行するとconfig.jsonの雛形が出力されます。
(docsearch-scraper) bash-3.2$ ./docsearch bootstrap
start url: https://lycheejam.hatenablog.com/ # クロール対象のサイトURLを入力
index_name is hatenablog [enter to confirm]: # <-index名がこれで良ければEnter
PUBLIC_CONFIG_FOLDER must be defined in environment # 以下が表示される
=============
{
"index_name": "hatenablog",
"start_urls": [
"https://lycheejam.hatenablog.com/"
],
"stop_urls": [],
"selectors": {
"lvl0": "FIXME h1",
"lvl1": "FIXME h2",
"lvl2": "FIXME h3",
"lvl3": "FIXME h4",
"lvl4": "FIXME h5",
"lvl5": "FIXME h6",
"text": "FIXME p, FIXME li"
}
}
=============
Config copied to clipboard [OK]上記コマンドで表示された雛形を元にconfig.json(hatenablog.json)ファイルを作成します。
(docsearch-scraper) bash-3.2$ vi hatenablog.jsonパット見なに書けば良いのかわからないんですがFIXMEの部分をクロール対象のサイト要素に合わせて変更します。
要素の指定はCSSの記入方法と同様です。
hatenablog.json
{
"index_name": "hatenablog",
"start_urls": ["https://lycheejam.hatenablog.com/"],
"stop_urls": [],
"selectors": {
"lvl0": ".entry-content h1",
"lvl1": ".entry-content h2",
"lvl2": ".entry-content h3",
"lvl3": ".entry-content h4",
"lvl4": ".entry-content h5",
"lvl5": ".entry-content h6",
"text": ".entry-content p, .entry-content li"
}
}はてなブログでF12押して要素を確認、レベル毎の要素を変更しました。
.entry-contentがエントリーのタイトル以下本文なのでそこを見るように指定してh1から順に優先度を設定した形です。
クロール中のINDEX作成のエラーについて
クロールの開始URL(start_urls)を自身のブログURLをルートとして指定しているのでコンテンツの無いページまでも見に行っちゃいますがここでは放置します。
クロールの実行
下準備が完了したのでクロールを実行してINDEXを作成します。
下記コマンドを実行することでクロールが開始されます。
(docsearch-scraper) bash-3.2$ ./docsearch run /<hoge>/hatenablog.json
# 省略Dockerの際と同様にAlgoliaのダッシュボードから確認可能です。
また、この方法の場合はローカルでの検証ツールが用意されているのでそれでも確認可能です。
playgroundを使ってクローリングの結果確認
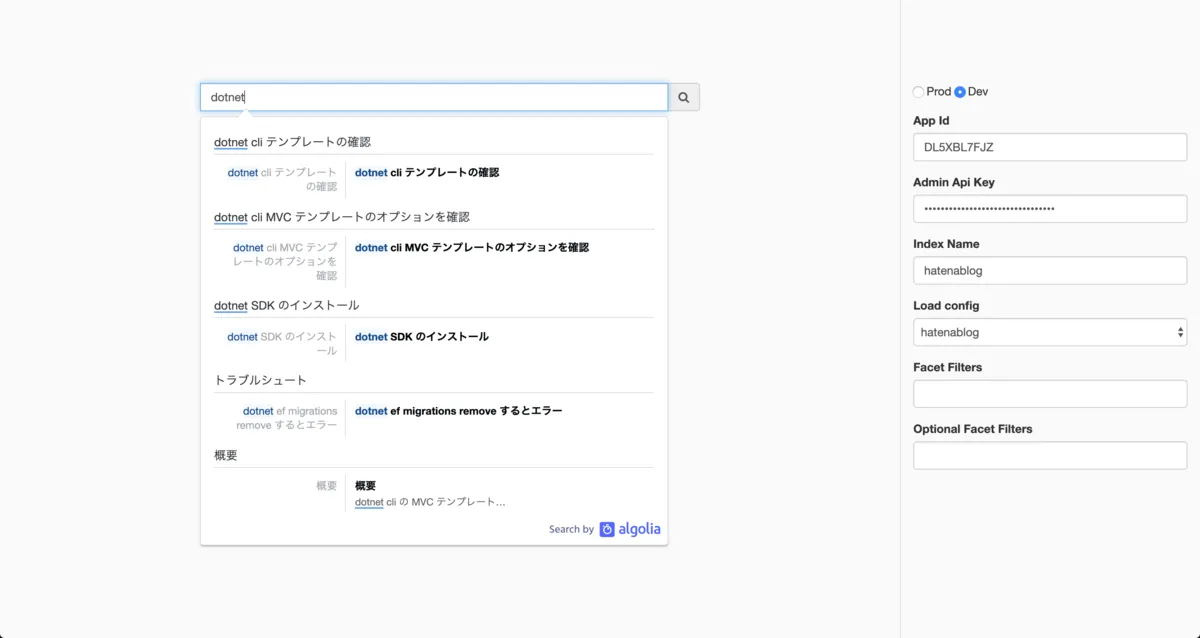
下記コマンドでローカルでの検証ツールが起動します。
(docsearch-scraper) bash-3.2$ ./docsearch playgroundブラウザが自動的に立ち上がるので立ち上がった画面で何かしら検索してみます。 自身のブログで全文検索できていることが確認できます。
雑感
探し方が悪いのかDocSearch-Scraperを使ってる人が全然いなくてしんどかったので誰かの役に立てれば幸いです。
VuePressでAlgolia DocSearchを使う方法を書こうと思ったんだけどボリュームが大きすぎたのでINDEX作成だけ別記事として作成しました。